

[ad_1]
As Roblox has grown over the previous 16+ years, so has the dimensions and complexity of the technical infrastructure that helps tens of millions of immersive 3D co-experiences. The variety of machines we assist has greater than tripled over the previous two years, from roughly 36,000 as of June 30, 2021 to almost 145,000 at present. Supporting these always-on experiences for folks all around the world requires greater than 1,000 inside providers. To assist us management prices and community latency, we deploy and handle these machines as a part of a custom-built and hybrid non-public cloud infrastructure that runs totally on premises.
Our infrastructure at the moment helps greater than 70 million each day lively customers world wide, together with the creators who depend on Roblox’s financial system for his or her companies. All of those tens of millions of individuals count on a really excessive stage of reliability. Given the immersive nature of our experiences, there may be a particularly low tolerance for lags or latency, not to mention outages. Roblox is a platform for communication and connection, the place folks come collectively in immersive 3D experiences. When persons are speaking as their avatars in an immersive house, even minor delays or glitches are extra noticeable than they’re on a textual content thread or a convention name.
In October, 2021, we skilled a system-wide outage. It began small, with a problem in a single element in a single knowledge heart. Nevertheless it unfold shortly as we have been investigating and finally resulted in a 73-hour outage. On the time, we shared each particulars about what occurred and a few of our early learnings from the problem. Since then, we’ve been finding out these learnings and dealing to extend the resilience of our infrastructure to the kinds of failures that happen in all large-scale methods attributable to elements like excessive site visitors spikes, climate, {hardware} failure, software program bugs, or simply people making errors. When these failures happen, how can we make sure that a problem in a single element, or group of elements, doesn’t unfold to the total system? This query has been our focus for the previous two years and whereas the work is ongoing, what we’ve carried out to this point is already paying off. For instance, within the first half of 2023, we saved 125 million engagement hours per thirty days in comparison with the primary half of 2022. Right this moment, we’re sharing the work we’ve already carried out, in addition to our longer-term imaginative and prescient for constructing a extra resilient infrastructure system.
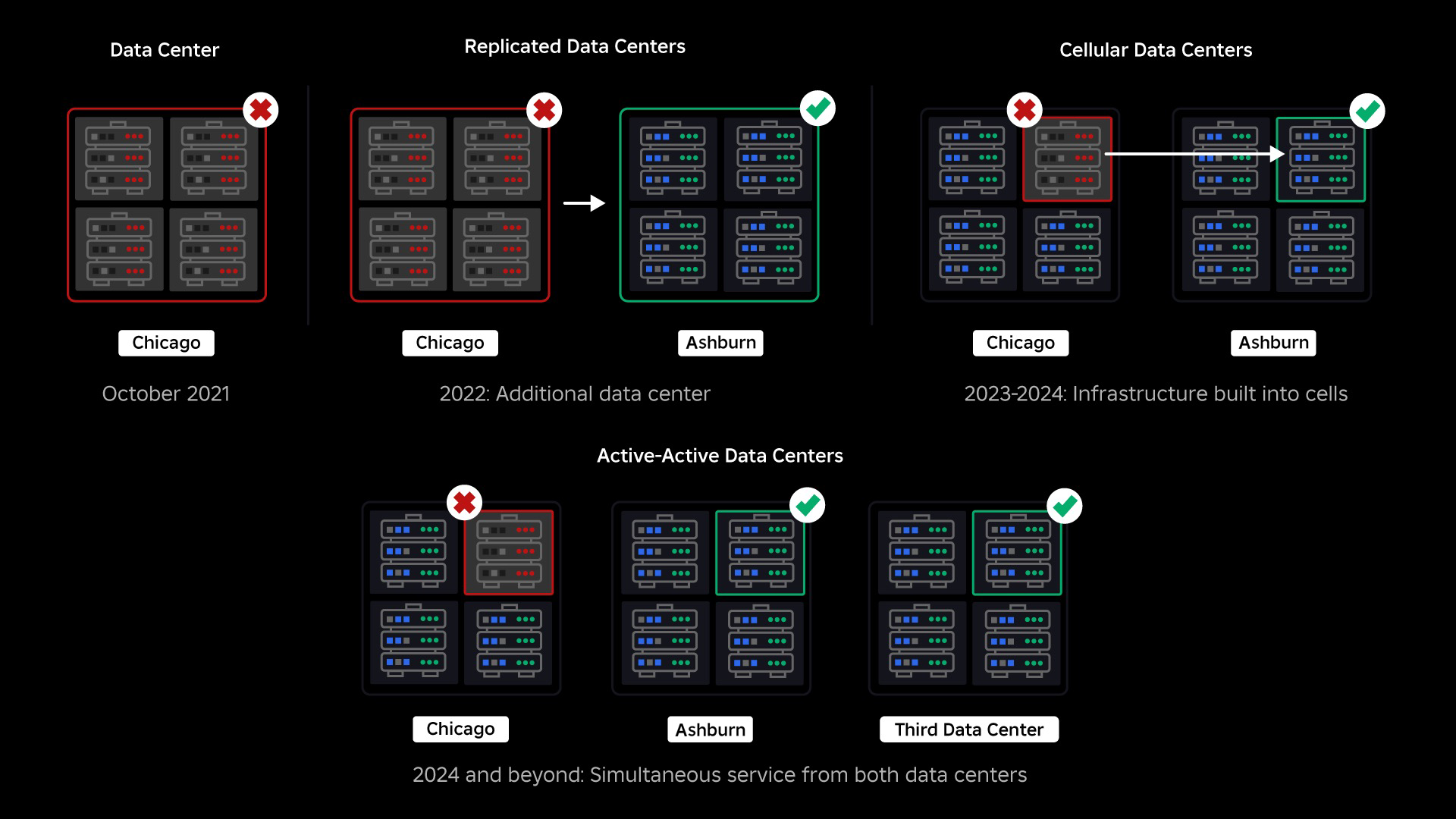
Constructing a Backstop
Inside large-scale infrastructure methods, small scale failures occur many instances a day. If one machine has a problem and needs to be taken out of service, that’s manageable as a result of most firms keep a number of situations of their back-end providers. So when a single occasion fails, others choose up the workload. To deal with these frequent failures, requests are usually set to robotically retry in the event that they get an error.
This turns into difficult when a system or particular person retries too aggressively, which might develop into a means for these small-scale failures to propagate all through the infrastructure to different providers and methods. If the community or a person retries persistently sufficient, it can finally overload each occasion of that service, and doubtlessly different methods, globally. Our 2021 outage was the results of one thing that’s pretty frequent in giant scale methods: A failure begins small then propagates by means of the system, getting huge so shortly it’s arduous to resolve in the beginning goes down.
On the time of our outage, we had one lively knowledge heart (with elements inside it performing as backup). We would have liked the power to fail over manually to a brand new knowledge heart when a problem introduced the prevailing one down. Our first precedence was to make sure we had a backup deployment of Roblox, so we constructed that backup in a brand new knowledge heart, situated in a distinct geographic area. That added safety for the worst-case situation: an outage spreading to sufficient elements inside an information heart that it turns into totally inoperable. We now have one knowledge heart dealing with workloads (lively) and one on standby, serving as backup (passive). Our long-term purpose is to maneuver from this active-passive configuration to an active-active configuration, through which each knowledge facilities deal with workloads, with a load balancer distributing requests between them based mostly on latency, capability, and well being. As soon as that is in place, we count on to have even greater reliability for all of Roblox and be capable of fail over almost instantaneously somewhat than over a number of hours. 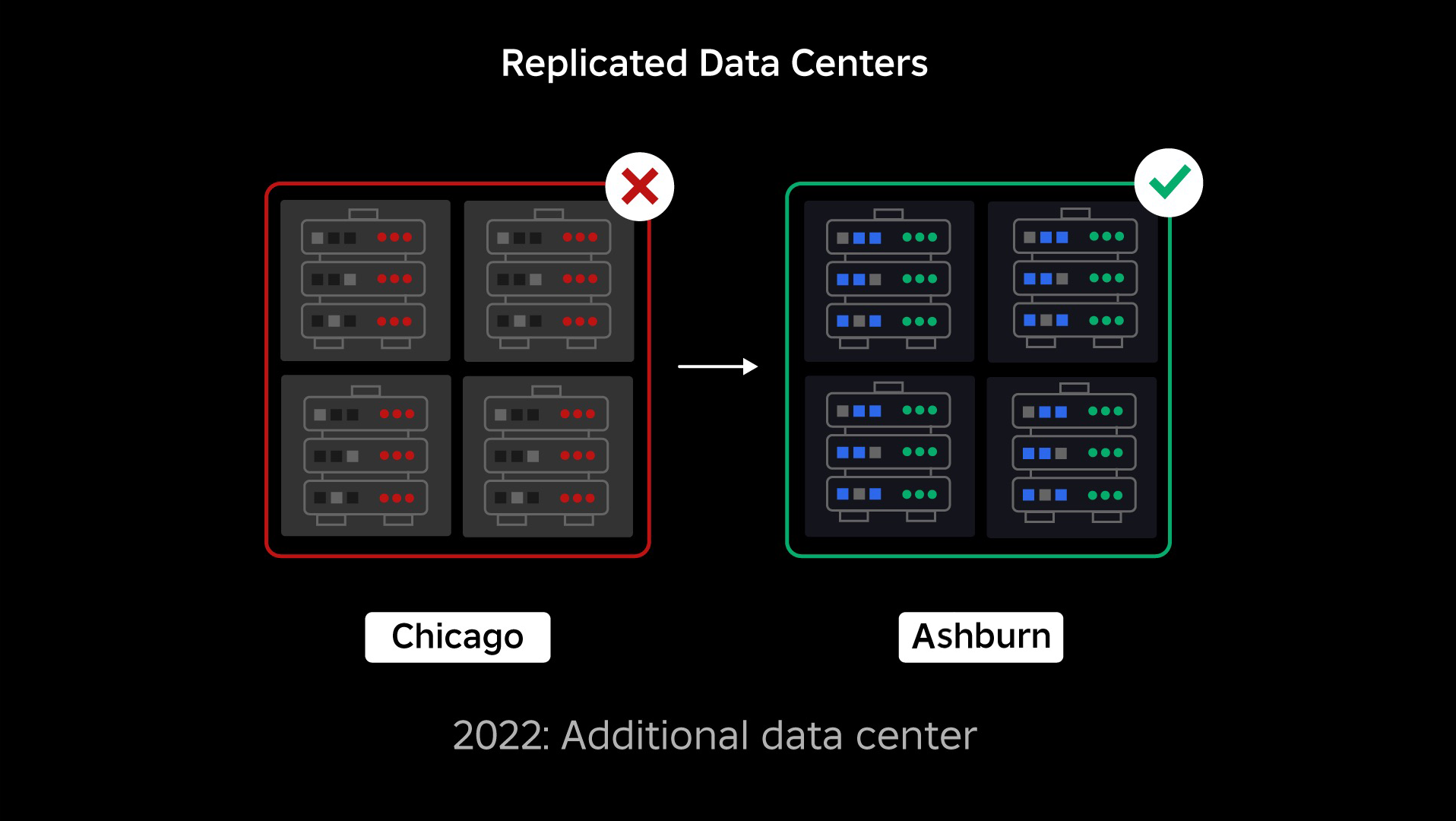
Transferring to a Mobile Infrastructure
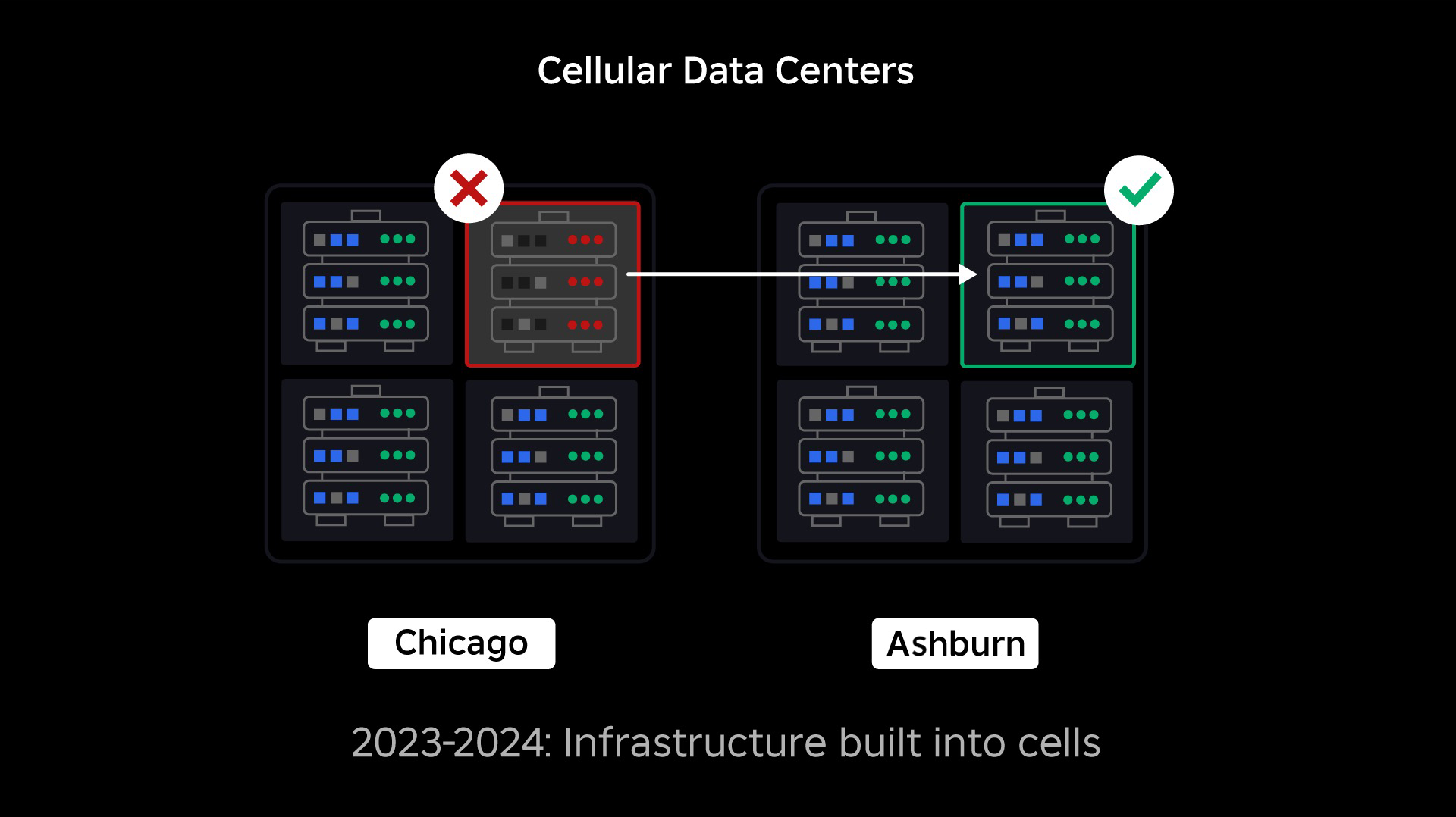
Our subsequent precedence was to create robust blast partitions inside every knowledge heart to cut back the potential of a whole knowledge heart failing. Cells (some firms name them clusters) are basically a set of machines and are how we’re creating these partitions. We replicate providers each inside and throughout cells for added redundancy. In the end, we wish all providers at Roblox to run in cells to allow them to profit from each robust blast partitions and redundancy. If a cell is now not practical, it could possibly safely be deactivated. Replication throughout cells allows the service to maintain operating whereas the cell is repaired. In some instances, cell restore would possibly imply an entire reprovisioning of the cell. Throughout the trade, wiping and reprovisioning a person machine, or a small set of machines, is pretty frequent, however doing this for a whole cell, which comprises ~1,400 machines, isn’t.
For this to work, these cells should be largely uniform, so we will shortly and effectively transfer workloads from one cell to a different. Now we have set sure necessities that providers want to satisfy earlier than they run in a cell. For instance, providers have to be containerized, which makes them far more moveable and prevents anybody from making configuration adjustments on the OS stage. We’ve adopted an infrastructure-as-code philosophy for cells: In our supply code repository, we embody the definition of every thing that’s in a cell so we will rebuild it shortly from scratch utilizing automated instruments.
Not all providers at the moment meet these necessities, so we’ve labored to assist service homeowners meet them the place doable, and we’ve constructed new instruments to make it straightforward emigrate providers into cells when prepared. For instance, our new deployment instrument robotically “stripes” a service deployment throughout cells, so service homeowners don’t have to consider the replication technique. This stage of rigor makes the migration course of far more difficult and time consuming, however the long-term payoff can be a system the place:
- It’s far simpler to comprise a failure and stop it from spreading to different cells;
- Our infrastructure engineers will be extra environment friendly and transfer extra shortly; and
- The engineers who construct the product-level providers which might be finally deployed in cells don’t must know or fear about which cells their providers are operating in.
Fixing Greater Challenges
Much like the best way hearth doorways are used to comprise flames, cells act as robust blast partitions inside our infrastructure to assist comprise no matter difficulty is triggering a failure inside a single cell. Ultimately, the entire providers that make up Roblox can be redundantly deployed within and throughout cells. As soon as this work is full, points might nonetheless propagate large sufficient to make a whole cell inoperable, however it might be extraordinarily tough for a problem to propagate past that cell. And if we reach making cells interchangeable, restoration can be considerably sooner as a result of we’ll be capable of fail over to a distinct cell and maintain the problem from impacting finish customers.
The place this will get difficult is separating these cells sufficient to cut back the chance to propagate errors, whereas holding issues performant and practical. In a fancy infrastructure system, providers want to speak with one another to share queries, info, workloads, and so forth. As we replicate these providers into cells, we should be considerate about how we handle cross-communication. In a really perfect world, we redirect site visitors from one unhealthy cell to different wholesome cells. However how can we handle a “question of demise”—one which’s inflicting a cell to be unhealthy? If we redirect that question to a different cell, it could possibly trigger that cell to develop into unhealthy in simply the best way we’re making an attempt to keep away from. We have to discover mechanisms to shift “good” site visitors from unhealthy cells whereas detecting and squelching the site visitors that’s inflicting cells to develop into unhealthy.
Within the quick time period, we’ve got deployed copies of computing providers to every compute cell so that almost all requests to the info heart will be served by a single cell. We’re additionally load balancing site visitors throughout cells. Trying additional out, we’ve begun constructing a next-generation service discovery course of that can be leveraged by a service mesh, which we hope to finish in 2024. This may permit us to implement subtle insurance policies that can permit cross-cell communication solely when it received’t negatively affect the failover cells. Additionally coming in 2024 can be a way for guiding dependent requests to a service model in the identical cell, which can decrease cross-cell site visitors and thereby scale back the chance of cross-cell propagation of failures.
At peak, greater than 70 % of our back-end service site visitors is being served out of cells and we’ve discovered quite a bit about the right way to create cells, however we anticipate extra analysis and testing as we proceed emigrate our providers by means of 2024 and past. As we progress, these blast partitions will develop into more and more stronger.
Migrating an always-on infrastructure
Roblox is a world platform supporting customers all around the world, so we will’t transfer providers throughout off-peak or “down time,” which additional complicates the method of migrating all of our machines into cells and our providers to run in these cells. Now we have tens of millions of always-on experiences that must proceed to be supported, at the same time as we transfer the machines they run on and the providers that assist them. After we began this course of, we didn’t have tens of 1000’s of machines simply sitting round unused and obtainable emigrate these workloads onto.
We did, nevertheless, have a small variety of extra machines that have been bought in anticipation of future development. To begin, we constructed new cells utilizing these machines, then migrated workloads to them. We worth effectivity in addition to reliability, so somewhat than going out and shopping for extra machines as soon as we ran out of “spare” machines we constructed extra cells by wiping and reprovisioning the machines we’d migrated off of. We then migrated workloads onto these reprovisioned machines, and began the method once more. This course of is advanced—as machines are changed and free as much as be constructed into cells, they don’t seem to be liberating up in a really perfect, orderly trend. They’re bodily fragmented throughout knowledge halls, leaving us to provision them in a piecemeal trend, which requires a hardware-level defragmentation course of to maintain the {hardware} areas aligned with large-scale bodily failure domains.
A portion of our infrastructure engineering workforce is targeted on migrating present workloads from our legacy, or “pre-cell,” surroundings into cells. This work will proceed till we’ve migrated 1000’s of various infrastructure providers and 1000’s of back-end providers into newly constructed cells. We count on this can take all of subsequent yr and probably into 2025, attributable to some complicating elements. First, this work requires sturdy tooling to be constructed. For instance, we want tooling to robotically rebalance giant numbers of providers after we deploy a brand new cell—with out impacting our customers. We’ve additionally seen providers that have been constructed with assumptions about our infrastructure. We have to revise these providers so they don’t rely on issues that might change sooner or later as we transfer into cells. We’ve additionally carried out each a solution to seek for recognized design patterns that received’t work nicely with mobile structure, in addition to a methodical testing course of for every service that’s migrated. These processes assist us head off any user-facing points attributable to a service being incompatible with cells.
Right this moment, near 30,000 machines are being managed by cells. It’s solely a fraction of our complete fleet, however it’s been a really clean transition to this point with no unfavorable participant affect. Our final purpose is for our methods to attain 99.99 % person uptime each month, which means we might disrupt not more than 0.01 % of engagement hours. Trade-wide, downtime can’t be utterly eradicated, however our purpose is to cut back any Roblox downtime to a level that it’s almost unnoticeable.
Future-proofing as we scale
Whereas our early efforts are proving profitable, our work on cells is much from carried out. As Roblox continues to scale, we’ll maintain working to enhance the effectivity and resiliency of our methods by means of this and different applied sciences. As we go, the platform will develop into more and more resilient to points, and any points that happen ought to develop into progressively much less seen and disruptive to the folks on our platform.
In abstract, up to now, we’ve got:
- Constructed a second knowledge heart and efficiently achieved lively/passive standing.
- Created cells in our lively and passive knowledge facilities and efficiently migrated greater than 70 % of our back-end service site visitors to those cells.
- Set in place the necessities and finest practices we’ll must observe to maintain all cells uniform as we proceed emigrate the remainder of our infrastructure.
- Kicked off a steady technique of constructing stronger “blast partitions” between cells.
As these cells develop into extra interchangeable, there can be much less crosstalk between cells. This unlocks some very fascinating alternatives for us when it comes to growing automation round monitoring, troubleshooting, and even shifting workloads robotically.
In September we additionally began operating lively/lively experiments throughout our knowledge facilities. That is one other mechanism we’re testing to enhance reliability and decrease failover instances. These experiments helped determine quite a lot of system design patterns, largely round knowledge entry, that we have to rework as we push towards turning into totally active-active. Total, the experiment was profitable sufficient to depart it operating for the site visitors from a restricted variety of our customers.
We’re excited to maintain driving this work ahead to convey higher effectivity and resiliency to the platform. This work on cells and active-active infrastructure, together with our different efforts, will make it doable for us to develop right into a dependable, excessive performing utility for tens of millions of individuals and to proceed to scale as we work to attach a billion folks in actual time.
[ad_2]
Source link
